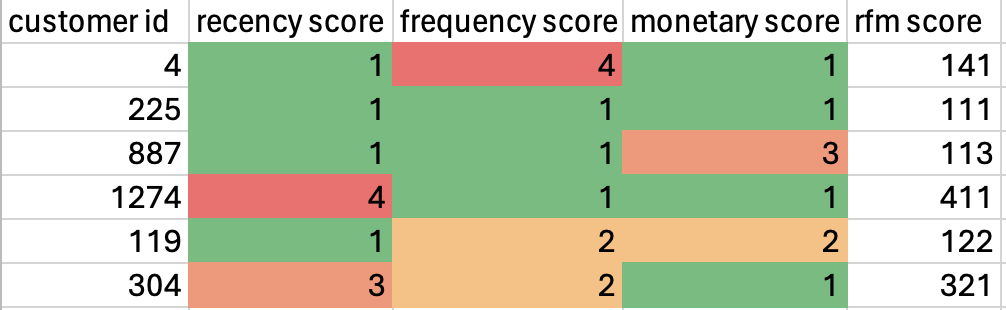
In this blog post, we will explore 1) the challenges encountered by data analysts, 2) three ways AI alleviates these issues, and 3) three unique advantages offered by Infoworks AI.
The Challenges Encountered by Data Analysts

Image: NicoElNino/Adobe Stock
Challenges with complexity of tasks
Data Analysts play a crucial role in organizations by handling various responsibilities. One of their primary tasks is data collection and analysis. This involves gathering business data from various sources, cleaning and transforming it, and performing detailed analysis. Another critical role is trend measurement, where analysts analyze data to measure and understand long-term trends. Additionally, they provide customer and profit insights, helping businesses gain a deeper understanding of customer behavior and profitability. Problem identification and solving is also a key responsibility, as analysts identify business problems through data and provide actionable solutions. Finally, Data Analysts present their findings to stakeholders in a simple, visual, and easily understandable manner, ensuring that the insights are accessible and actionable.
To be successful, Data Analysts possess a diverse skill set. Quantitative skills are essential, including strong mathematical and statistical abilities, such as budgeting and probability. Qualitative skills enable them to think creatively, to interpret information, draw conclusions, and think critically. They also possess a strong business understanding to design better business models. Technical skills are also a vital part of a Data Analyst’s toolkit. Proficiency in databases, software tools, and scripting languages is necessary, along with the ability to present data insights effectively.
Challenges with time consumption
Despite their expertise, Data Analysts face significant challenges meeting the demands of the business and can spend 80% of their time assembling the data needed for analysis. Cleaning and transforming data can be time-consuming. Query writing is another area where analysts encounter difficulties; writing complex SQL queries requires expertise and can be prone to errors. Visualization is an additional pain point, as creating charts and visual reports takes extra time. Many tasks in a Data Analyst’s role are repetitive and could benefit from automation, highlighting the need for tools and technologies that can streamline these processes and enhance efficiency.
3 Ways AI Makes a Data Analyst’s Job Easier
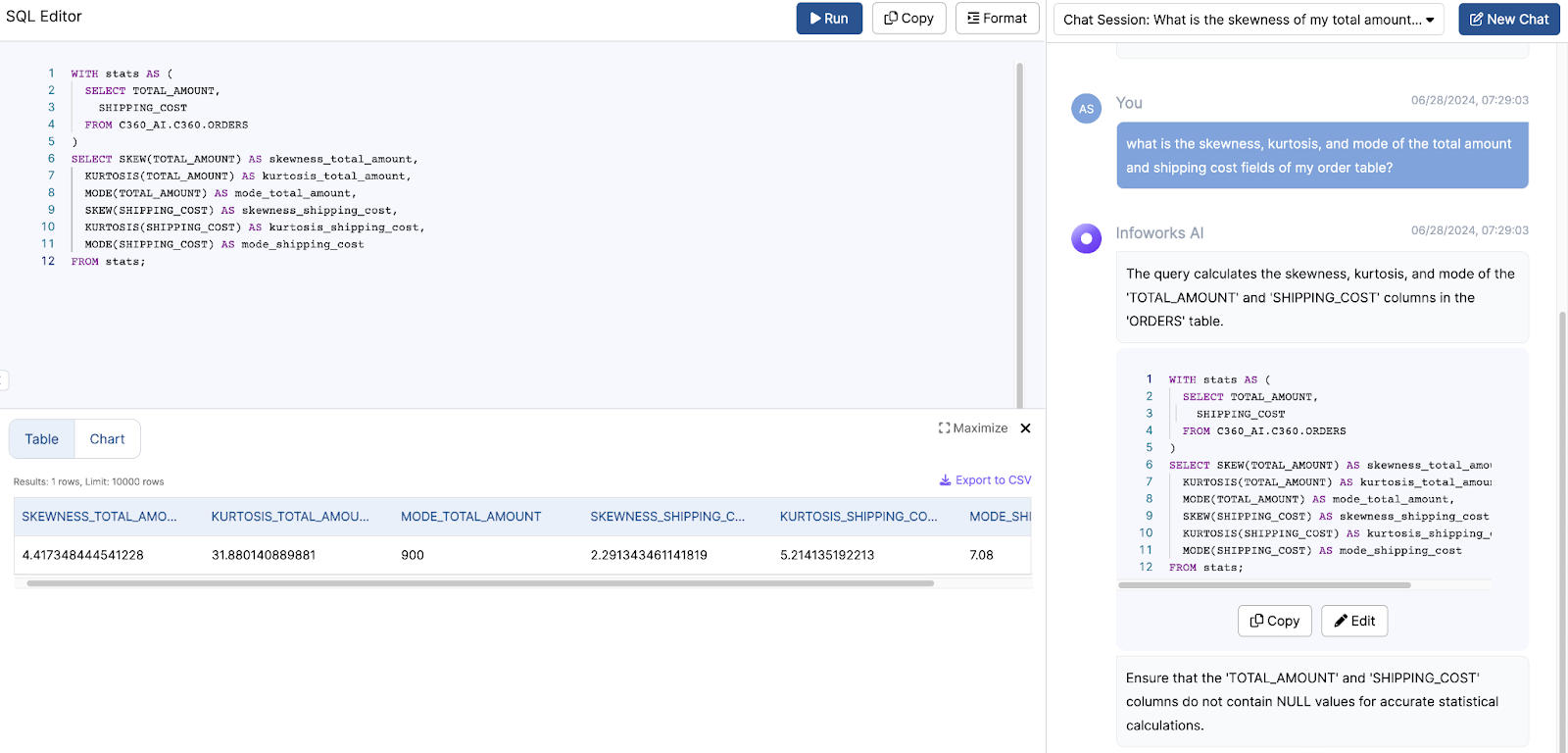
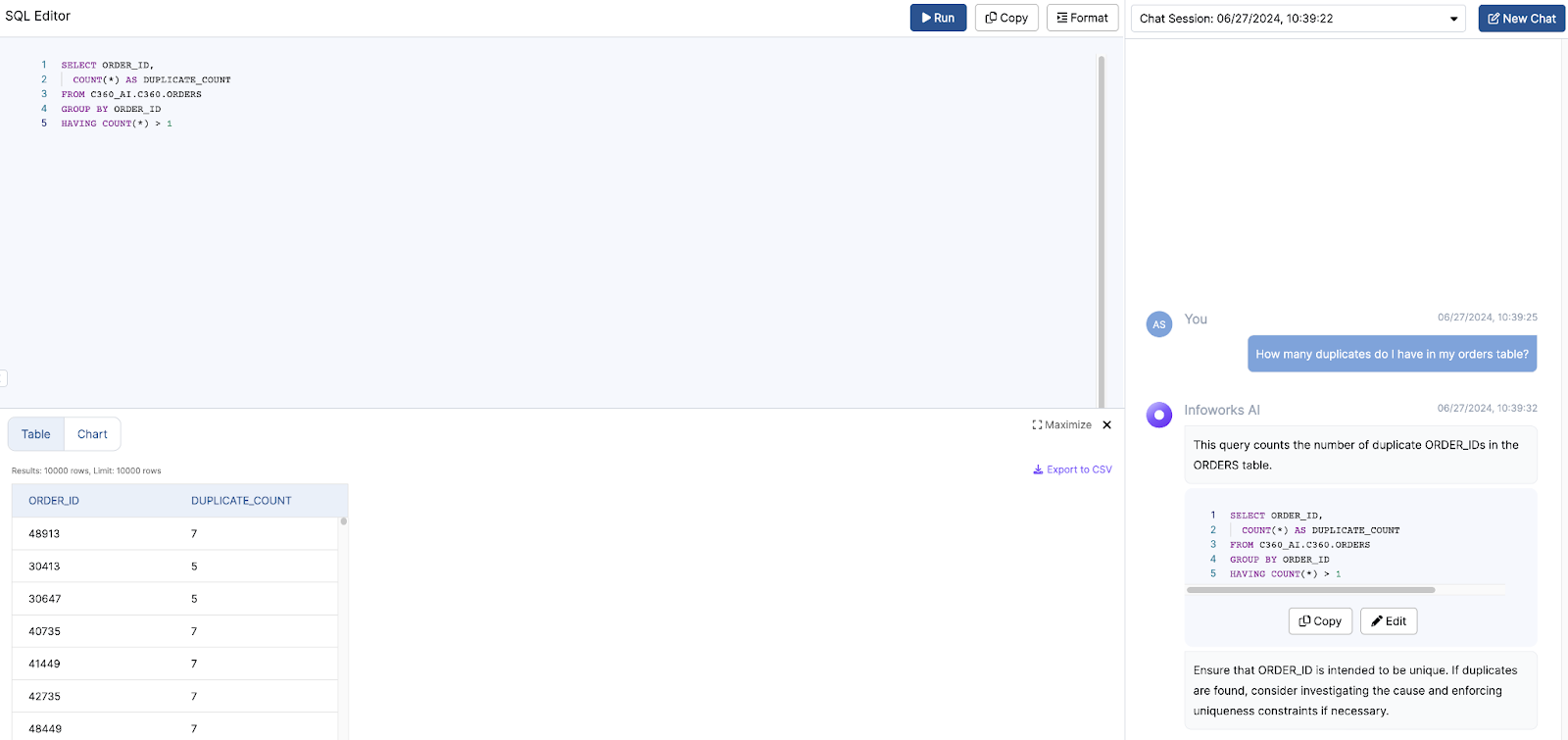
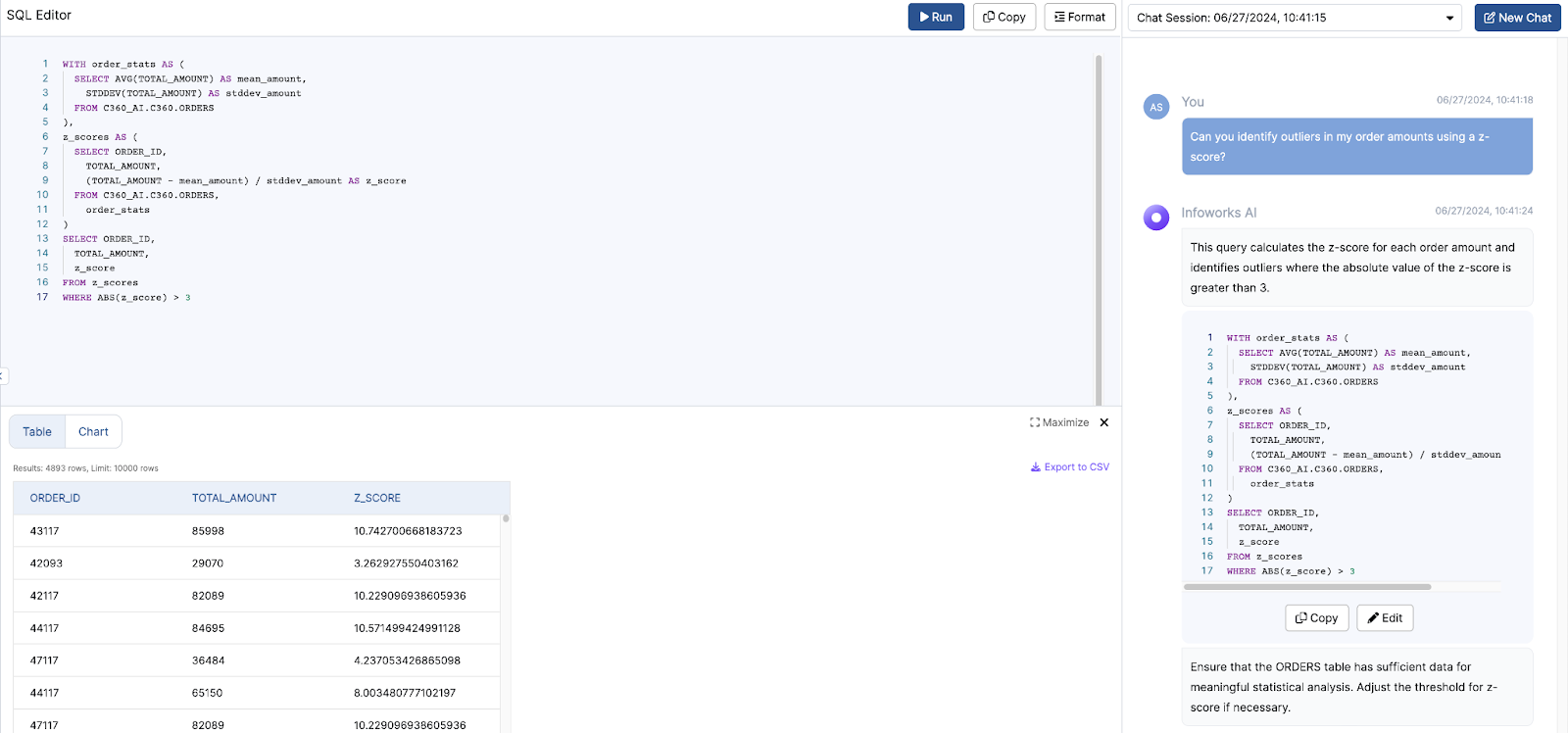
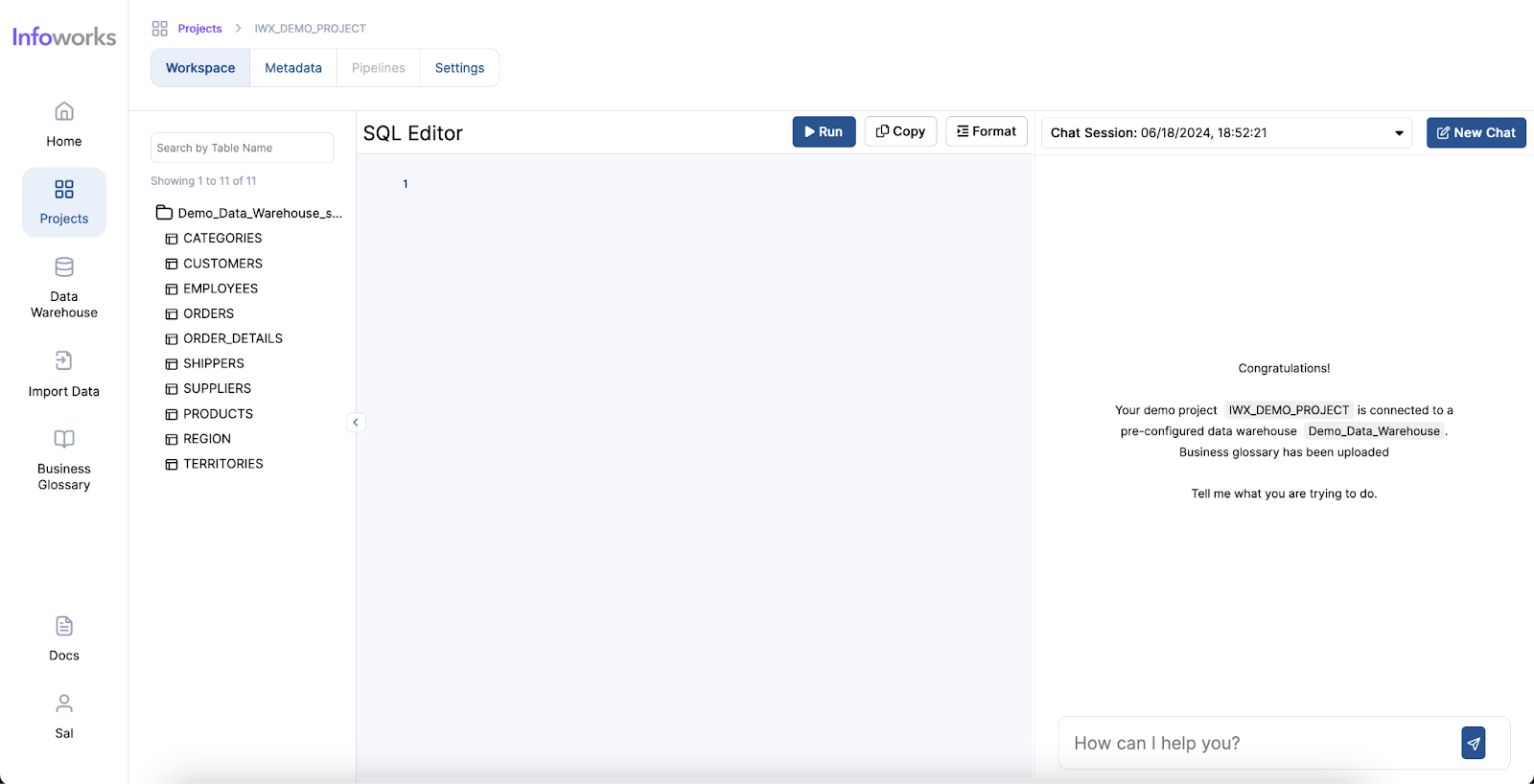
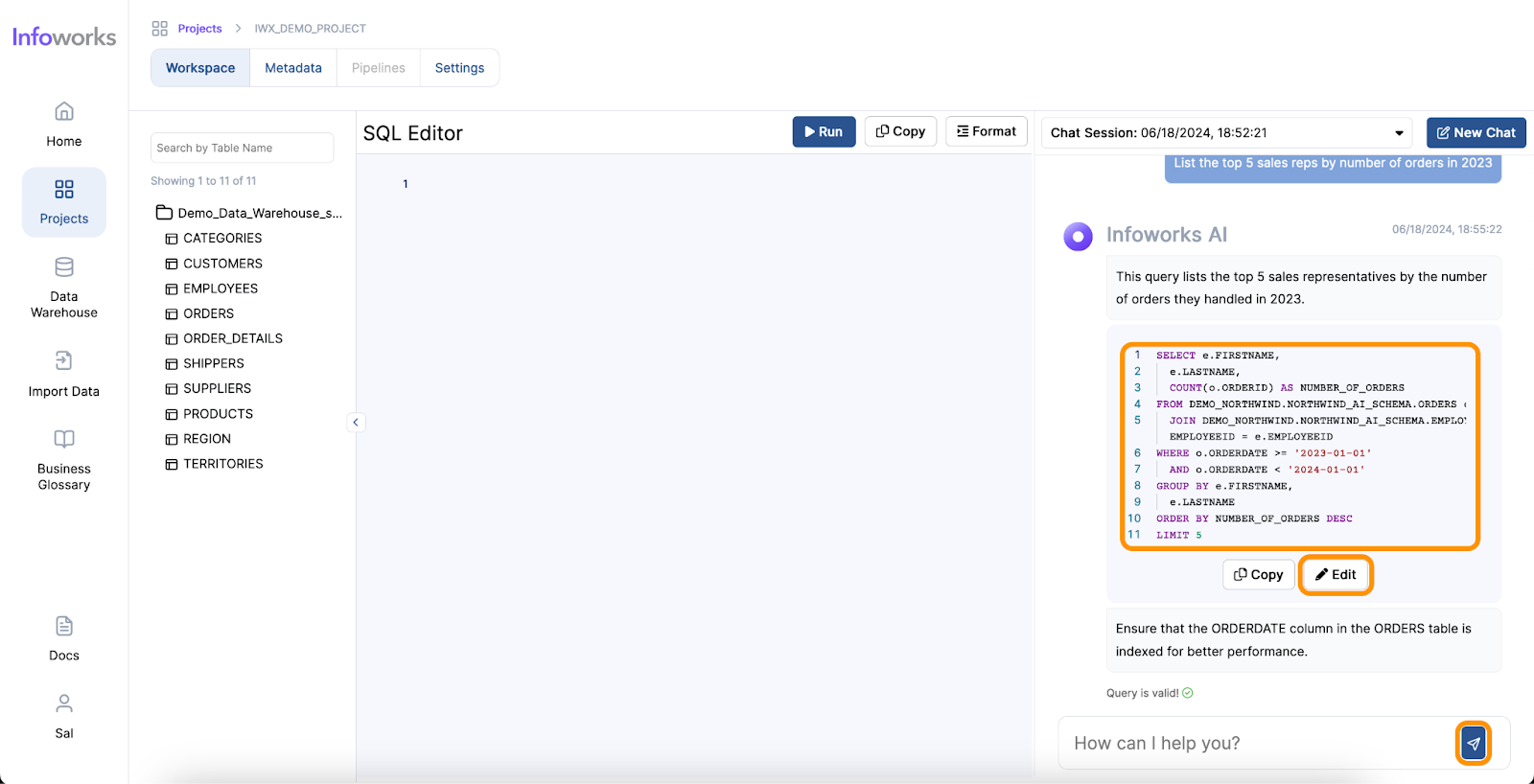
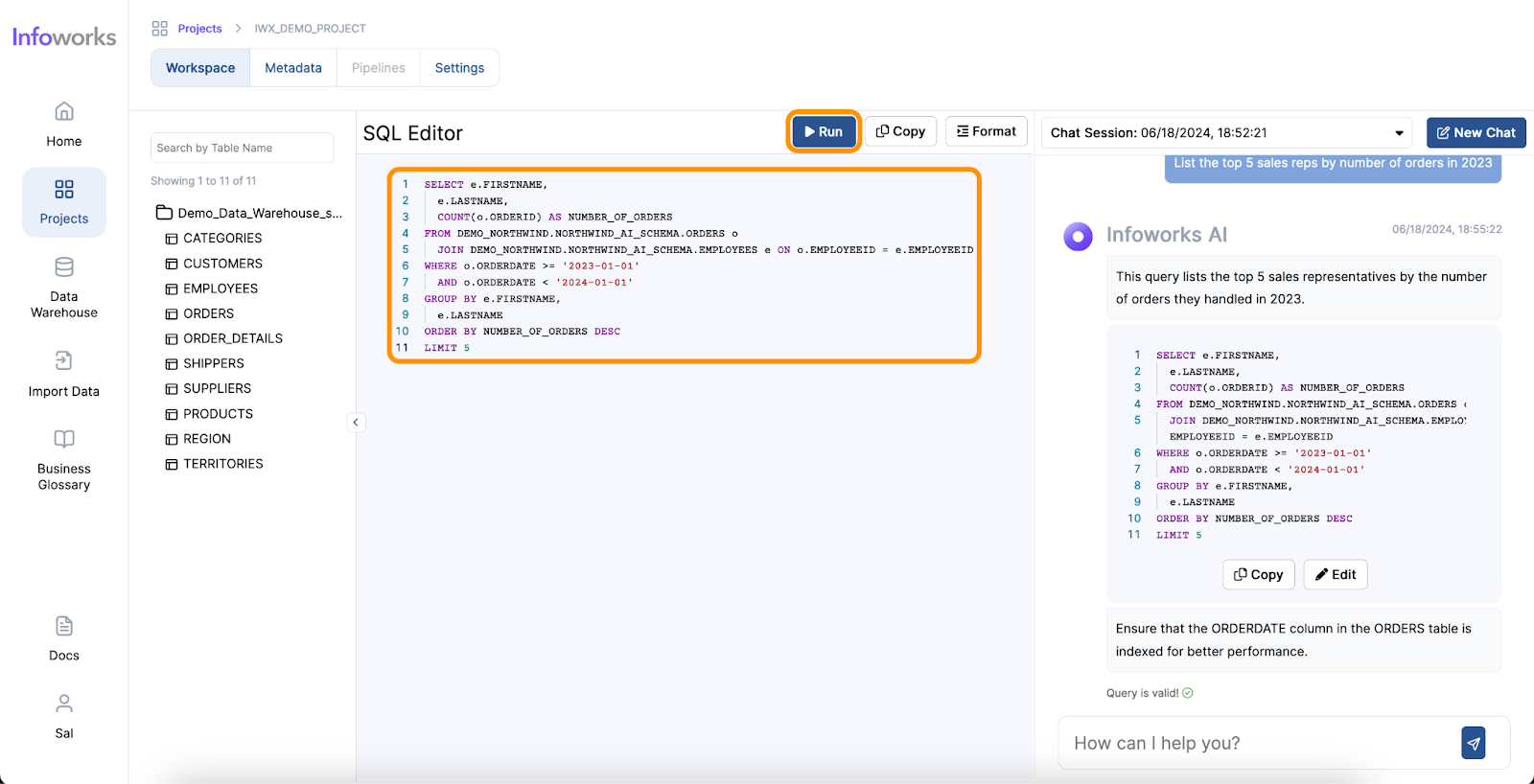
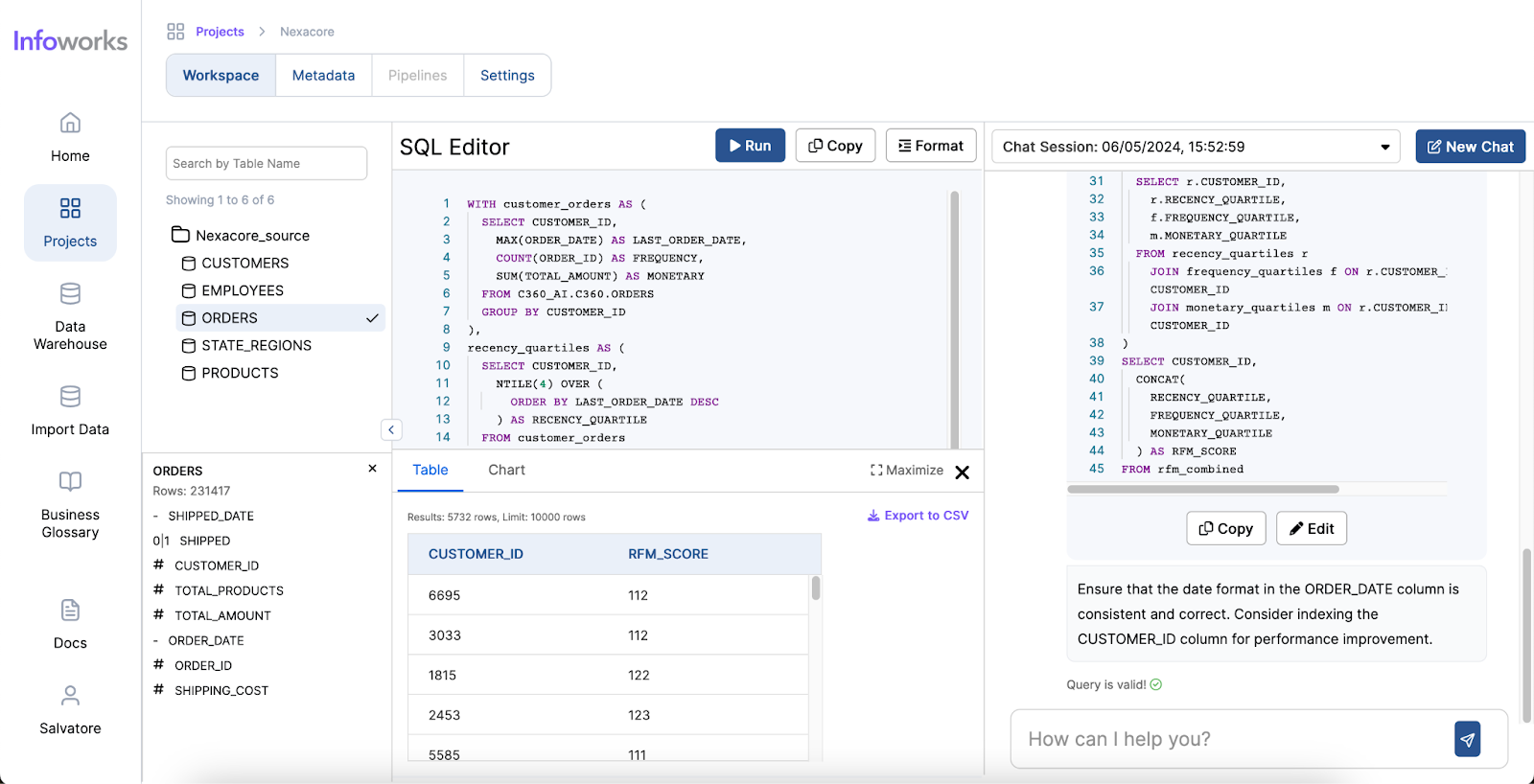
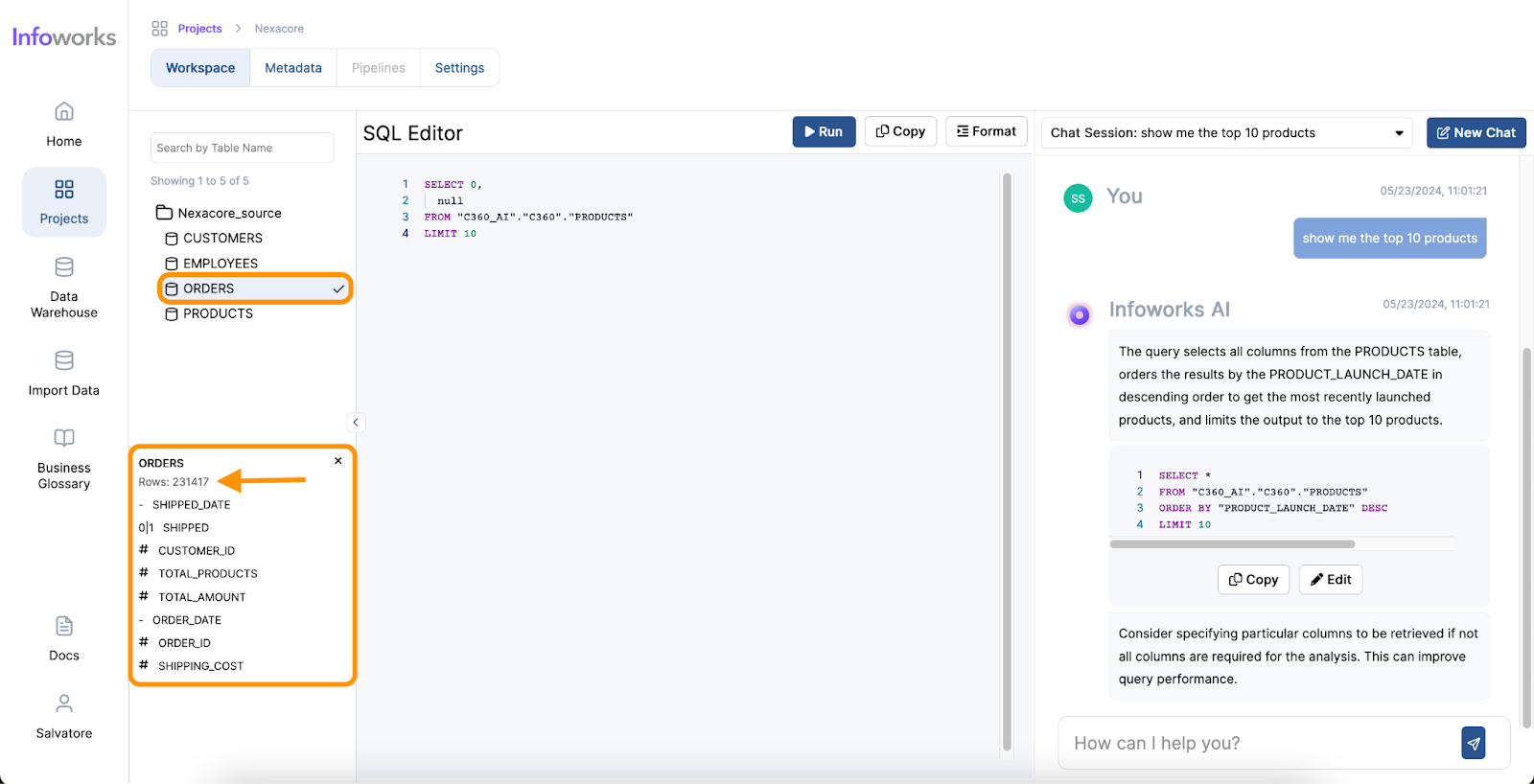
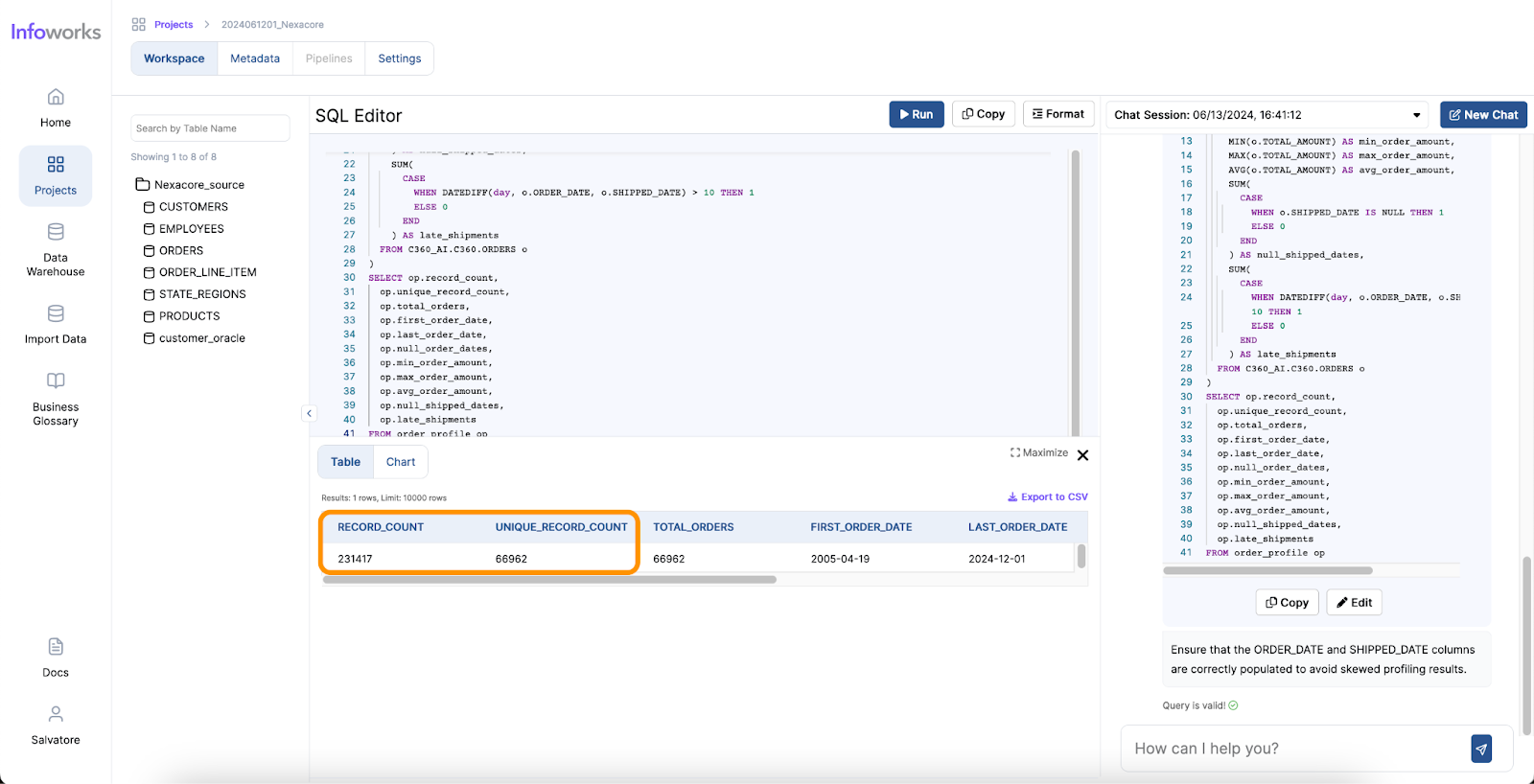
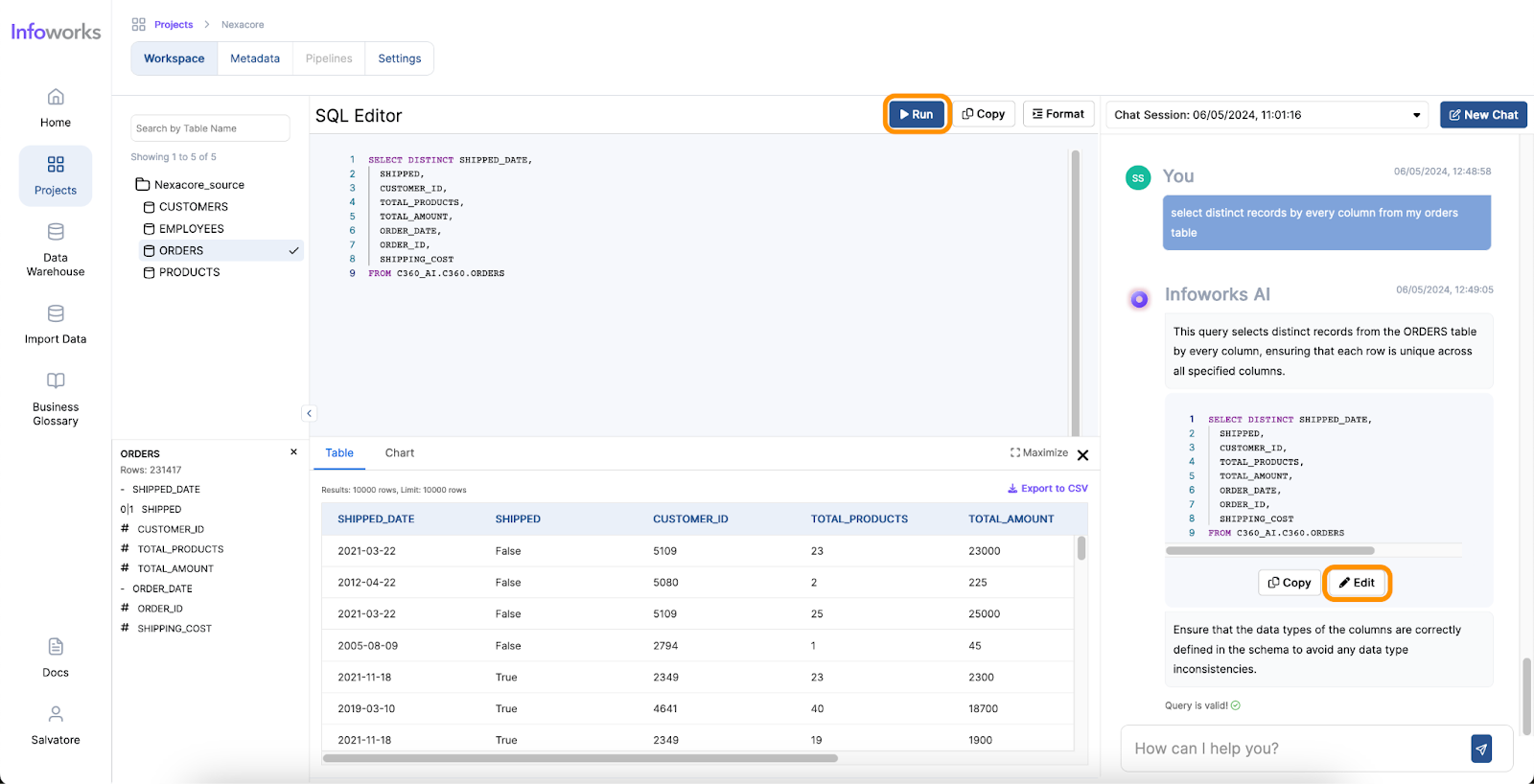
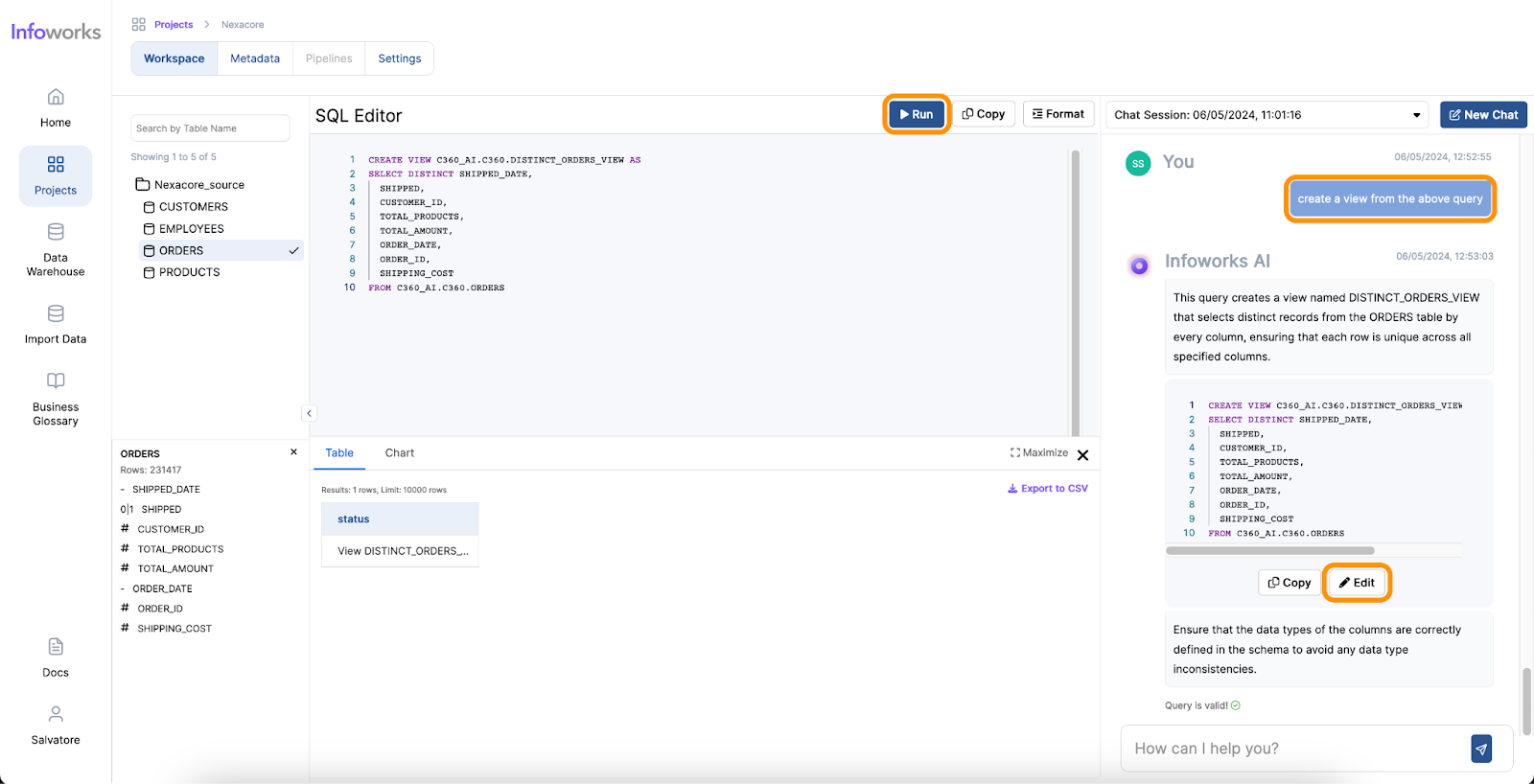
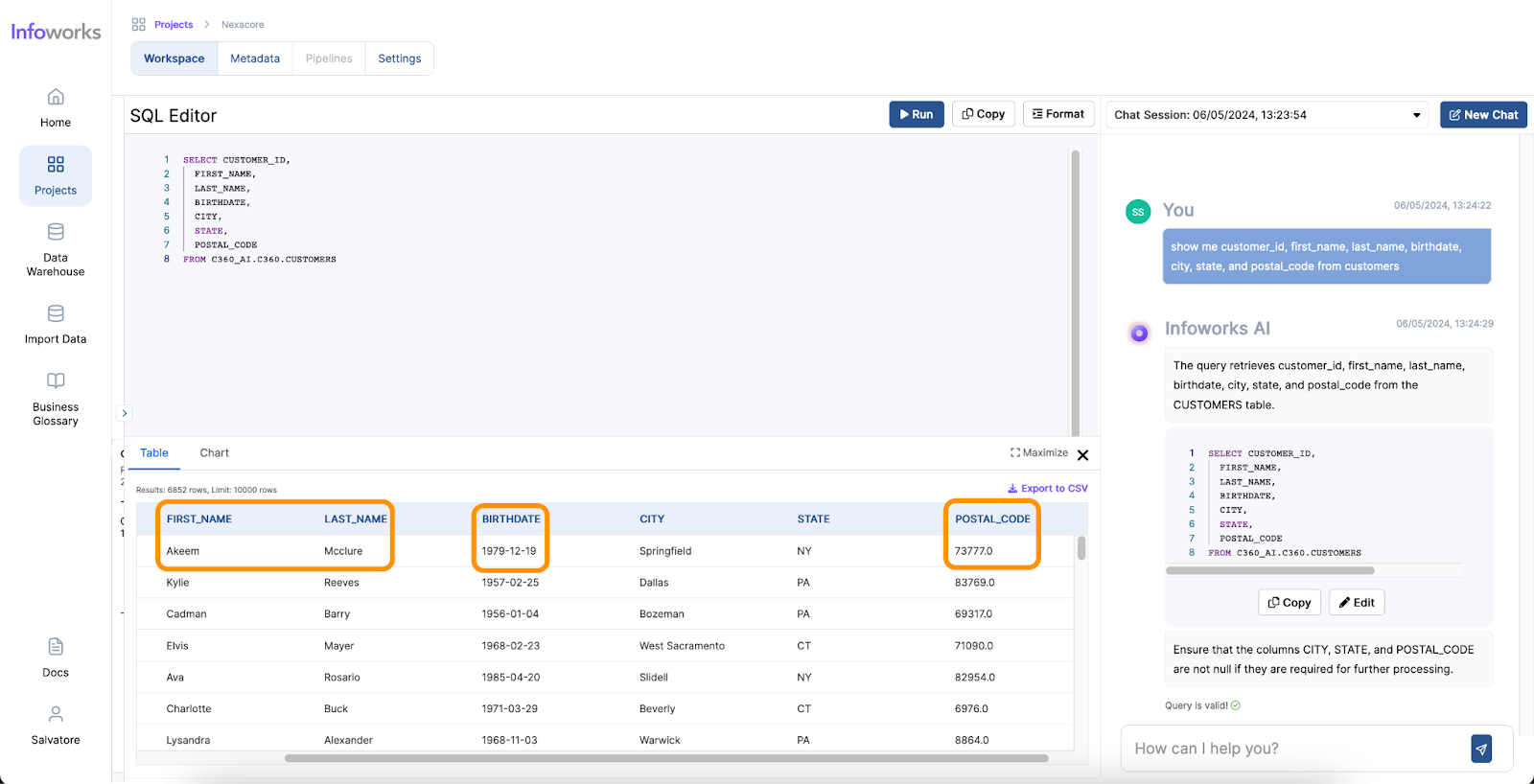
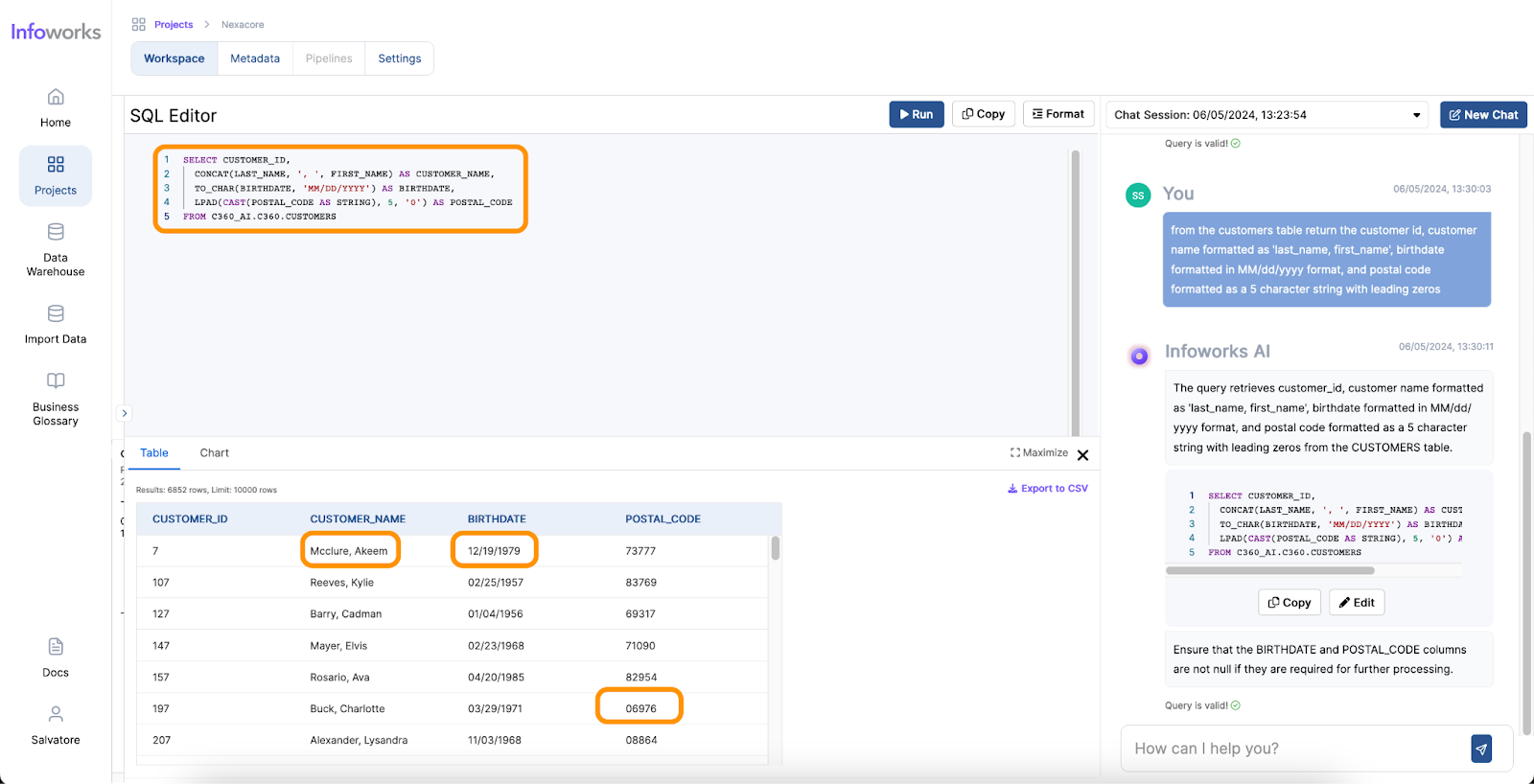
AI-powered text-to-SQL tools simplify and accelerate the work of Data Analysts by providing an intuitive way to generate SQL queries from natural language inputs. Here’s how they address the common pain points:
Time Saved
One of the most significant benefits of AI for Data Analysts is the time saved in performing complex tasks. Traditionally, generating queries and visualizations can take hours or even days, depending on the complexity of the data and the analysis required. However, with AI, these tasks can be completed in minutes. AI tools streamline the process, allowing analysts to focus on interpreting the results and making data-driven decisions more quickly.
Ease of Use
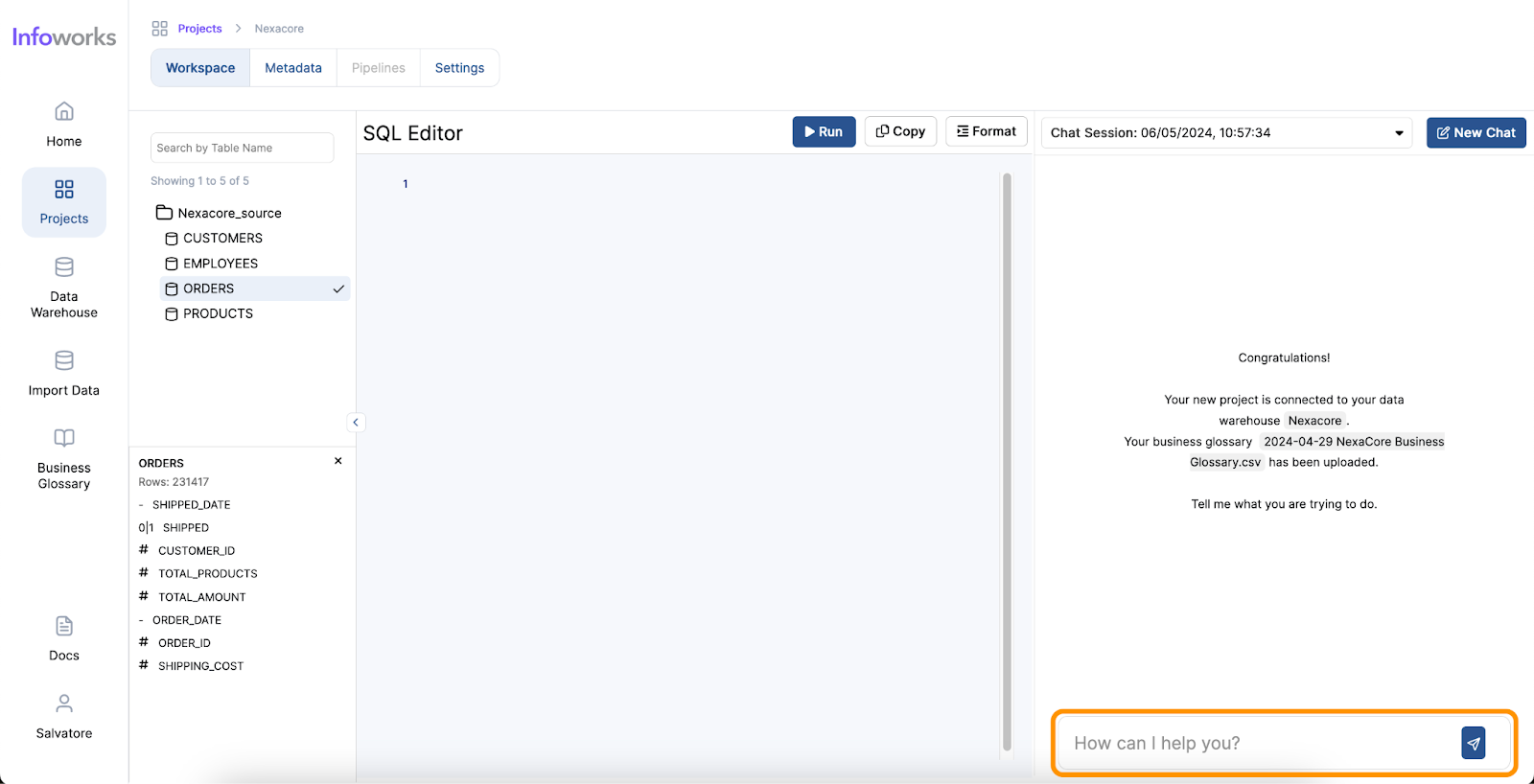
The user-friendly nature of AI tools significantly enhances the ease of use for Data Analysts. These tools often come with intuitive interfaces where analysts can input queries in natural language, reducing the need for extensive training. The minimal learning curve means that even those with limited technical expertise can quickly start using AI tools to generate insights. AI tools also enhance analysts’ skill sets by offering quantitative assistance, such as predictive analytics and pattern recognition, as well as qualitative assistance, like natural language processing and sentiment analysis. Furthermore, AI provides technical assistance by automating query generation, data visualization, data cleansing, and task automation.
Cost-Effectiveness
AI also offers a cost-effective solution for data analysis. Traditional methods often require significant investment in multiple tools and training resources to equip analysts with the necessary skills and software. In contrast, AI platforms provide multiple functionalities within a single, integrated solution. This not only reduces the overall cost but also optimizes the use of resources, making it easier for organizations to manage their data analysis processes efficiently.
3 Key Differentiating factors of Infoworks AI:
Superior Accuracy in Text-to-SQL
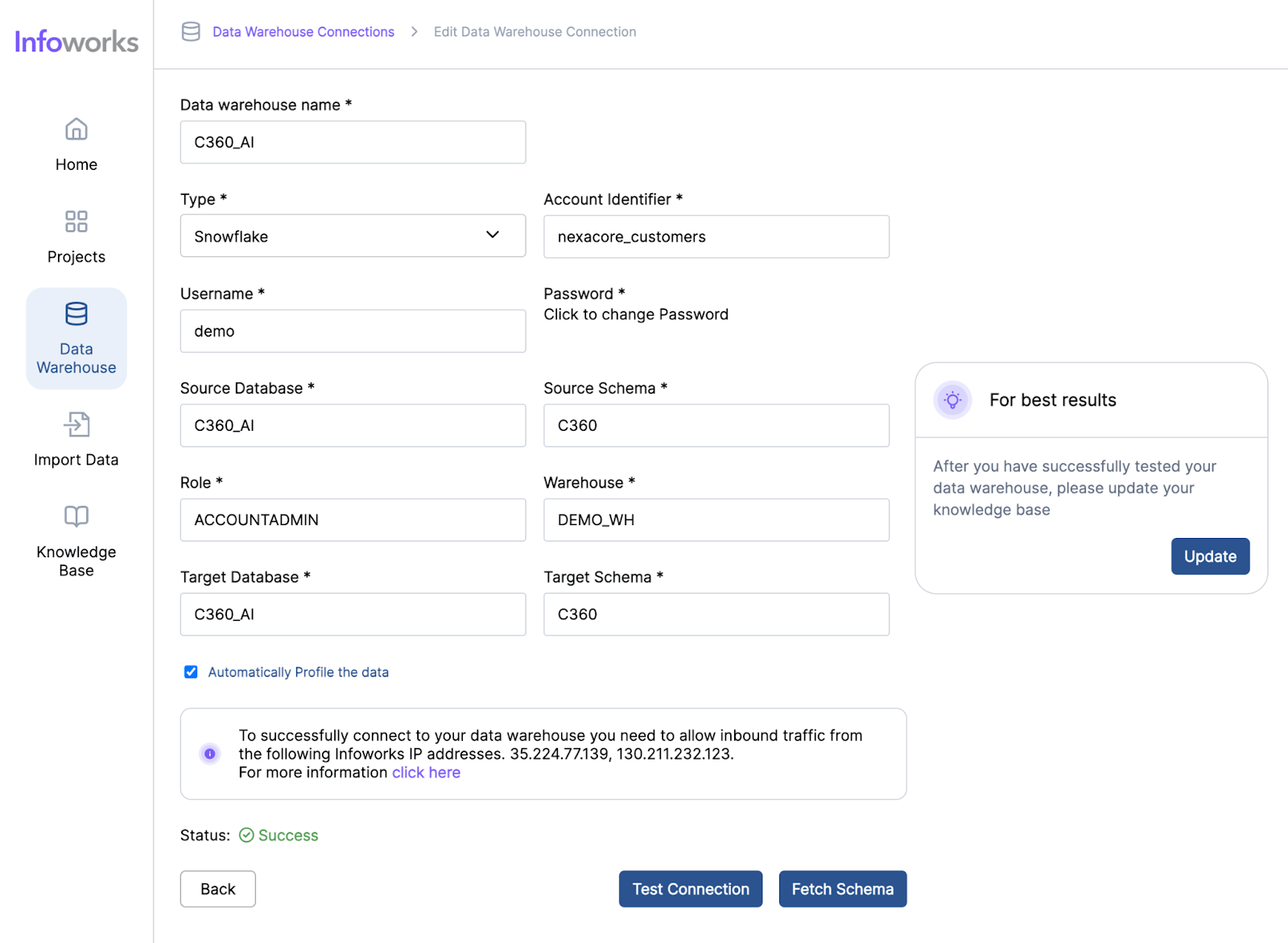
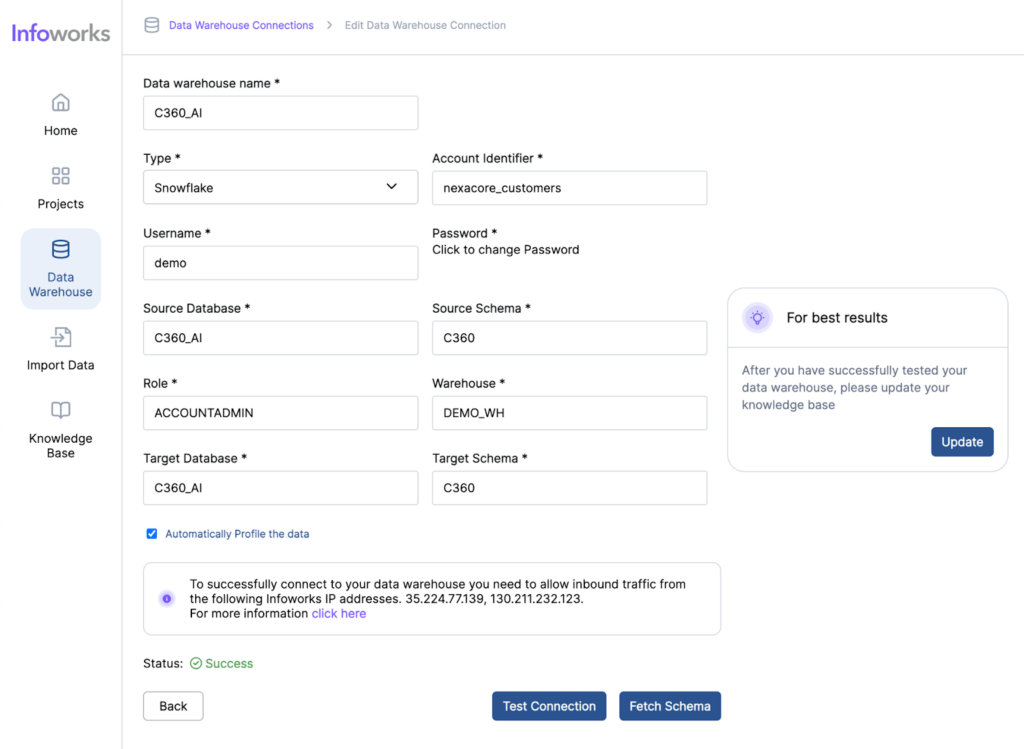
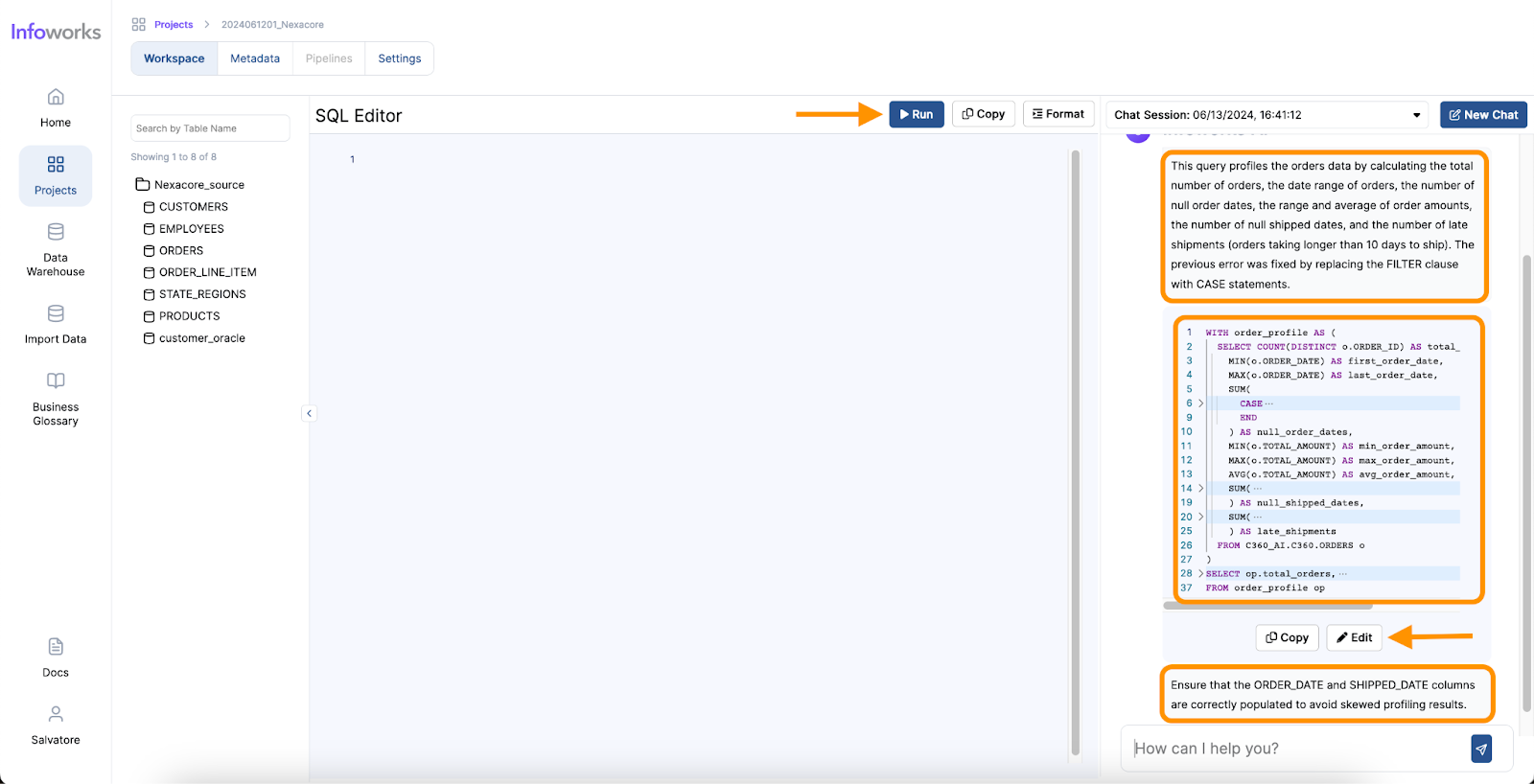
One of the standout features of Infoworks AI is its superior accuracy in text-to-SQL conversions. While traditional text-to-SQL tools typically achieve an accuracy rate of around 60-65%, Infoworks AI leverages continuous improvements and advanced AI algorithms to reach accuracy levels of 75-85%. It overcomes the common challenges of text-to-SQL generation through advanced prompting techniques, utilizing insights from extensive benchmarking on diverse datasets. Additionally, Infoworks AI incorporates sophisticated AI methods to maximize contextual accuracy, allowing it to better understand the user’s intent and context. This results in more accurate and relevant query generation, streamlining the data analysis process. This significant enhancement in accuracy ensures that data analysts can rely on the tool for precise query generation, reducing the likelihood of errors and increasing overall efficiency.
Comprehensive Supported Operations and Functionalities
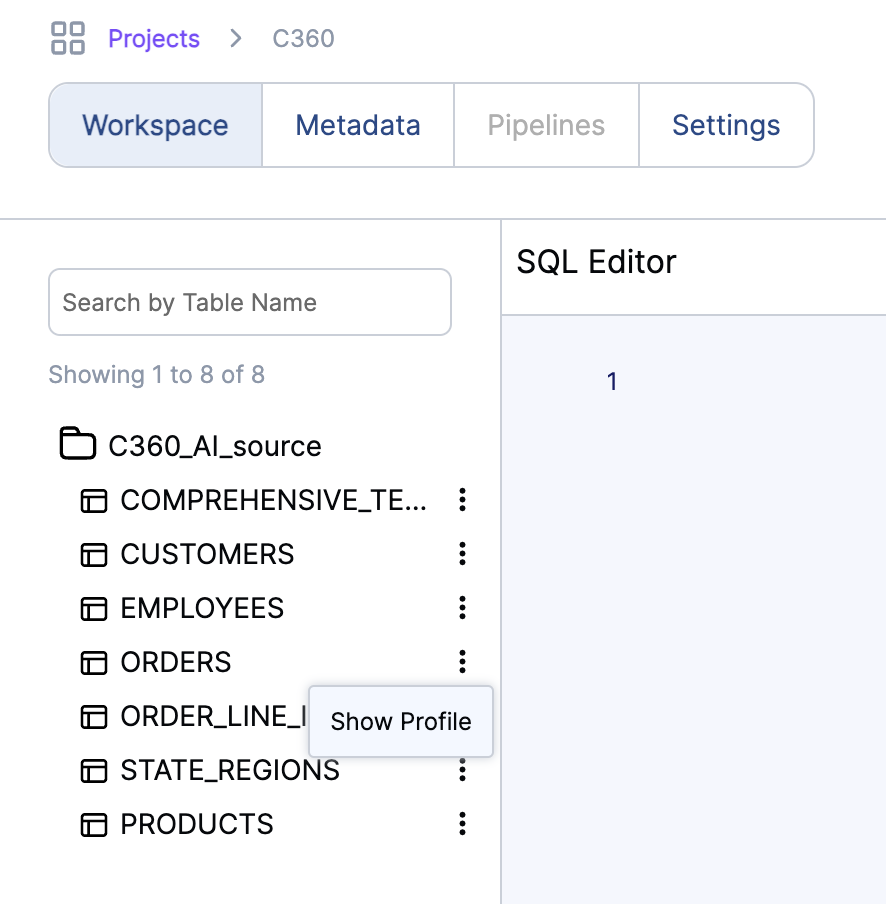
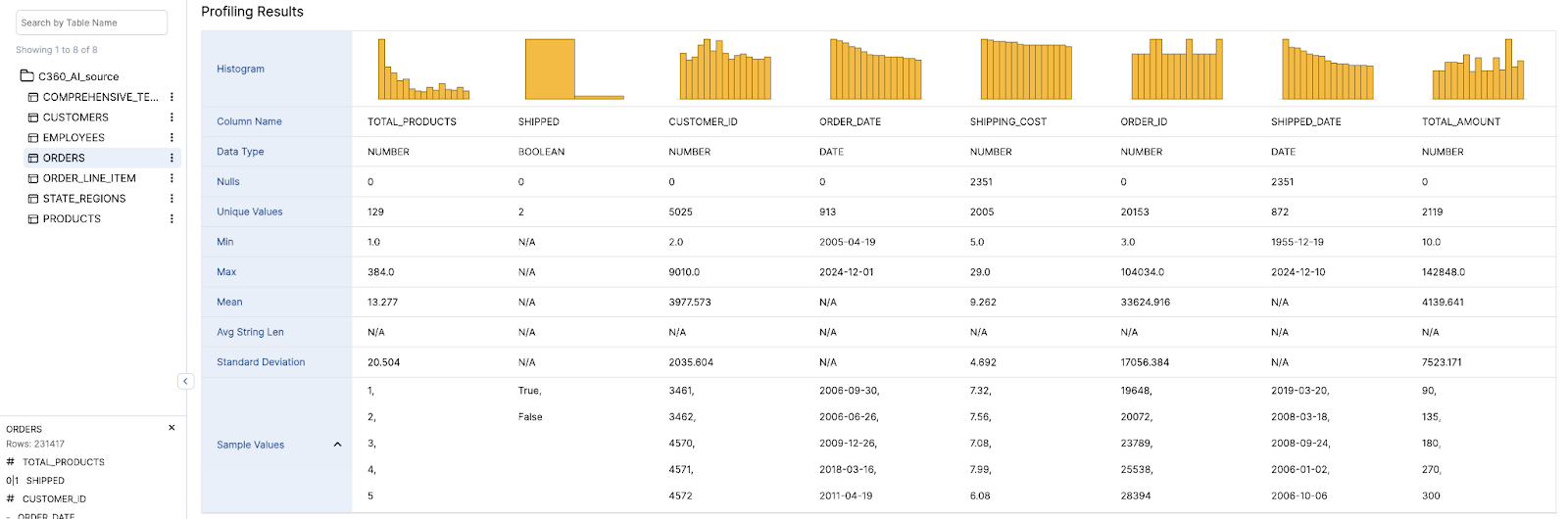
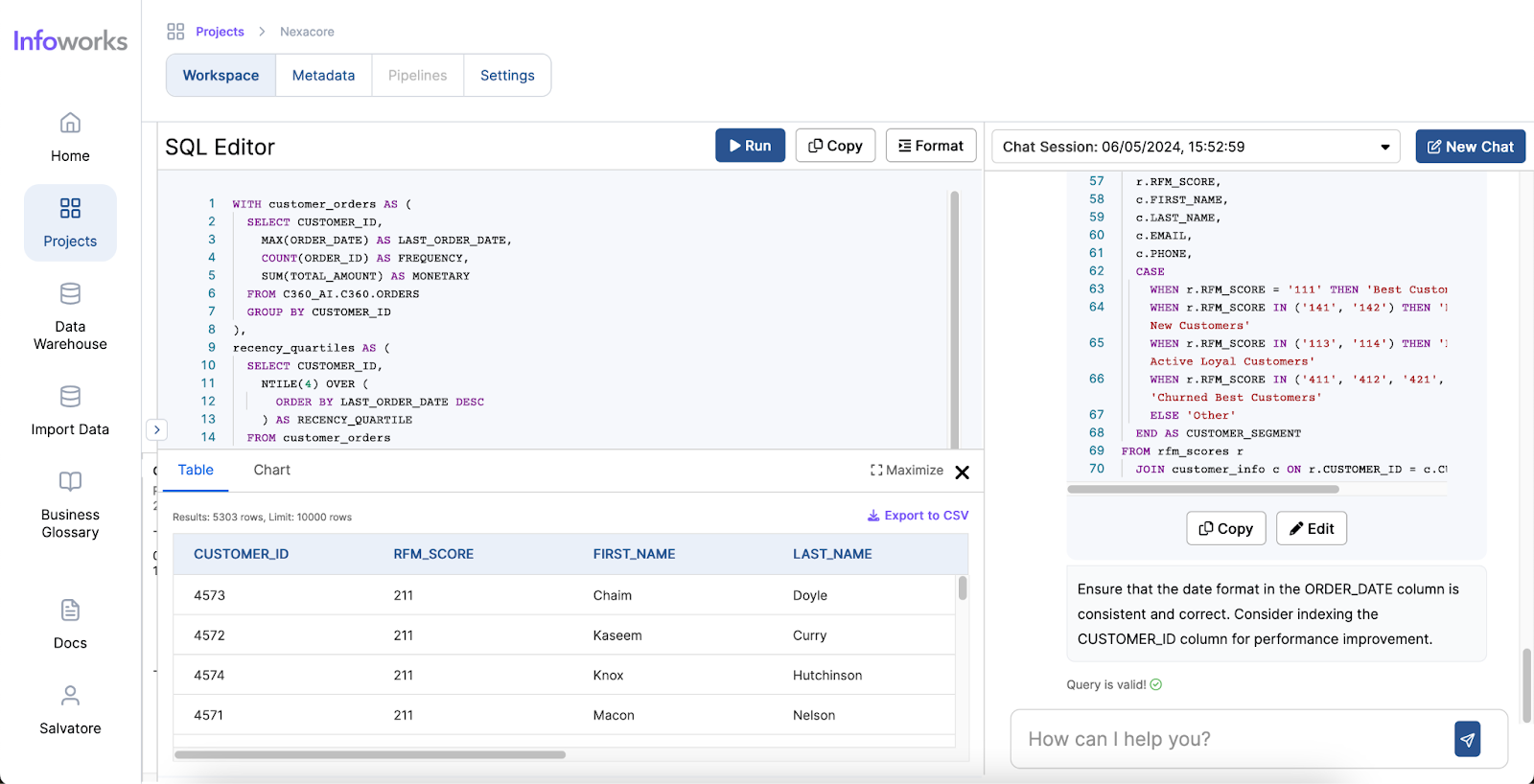
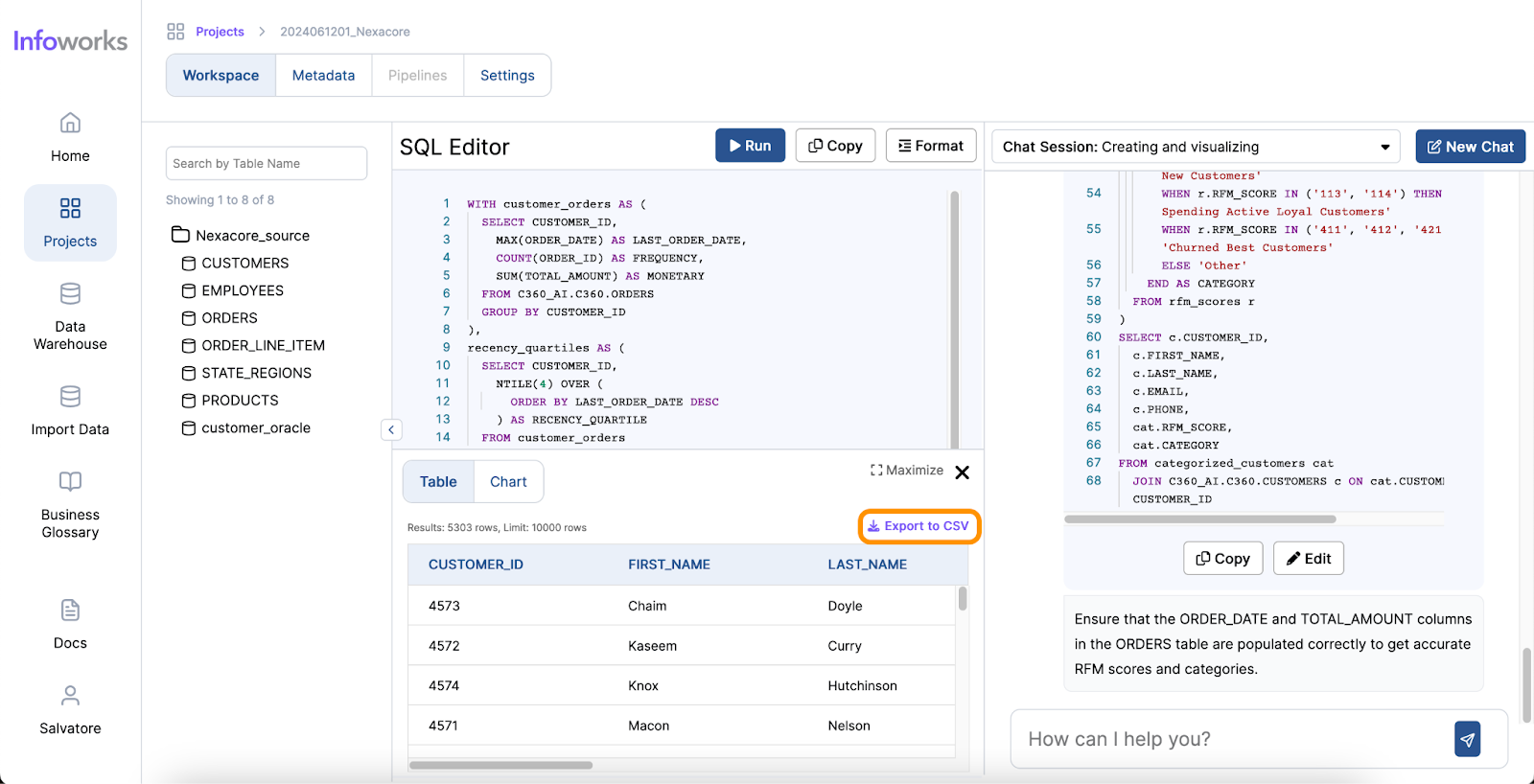
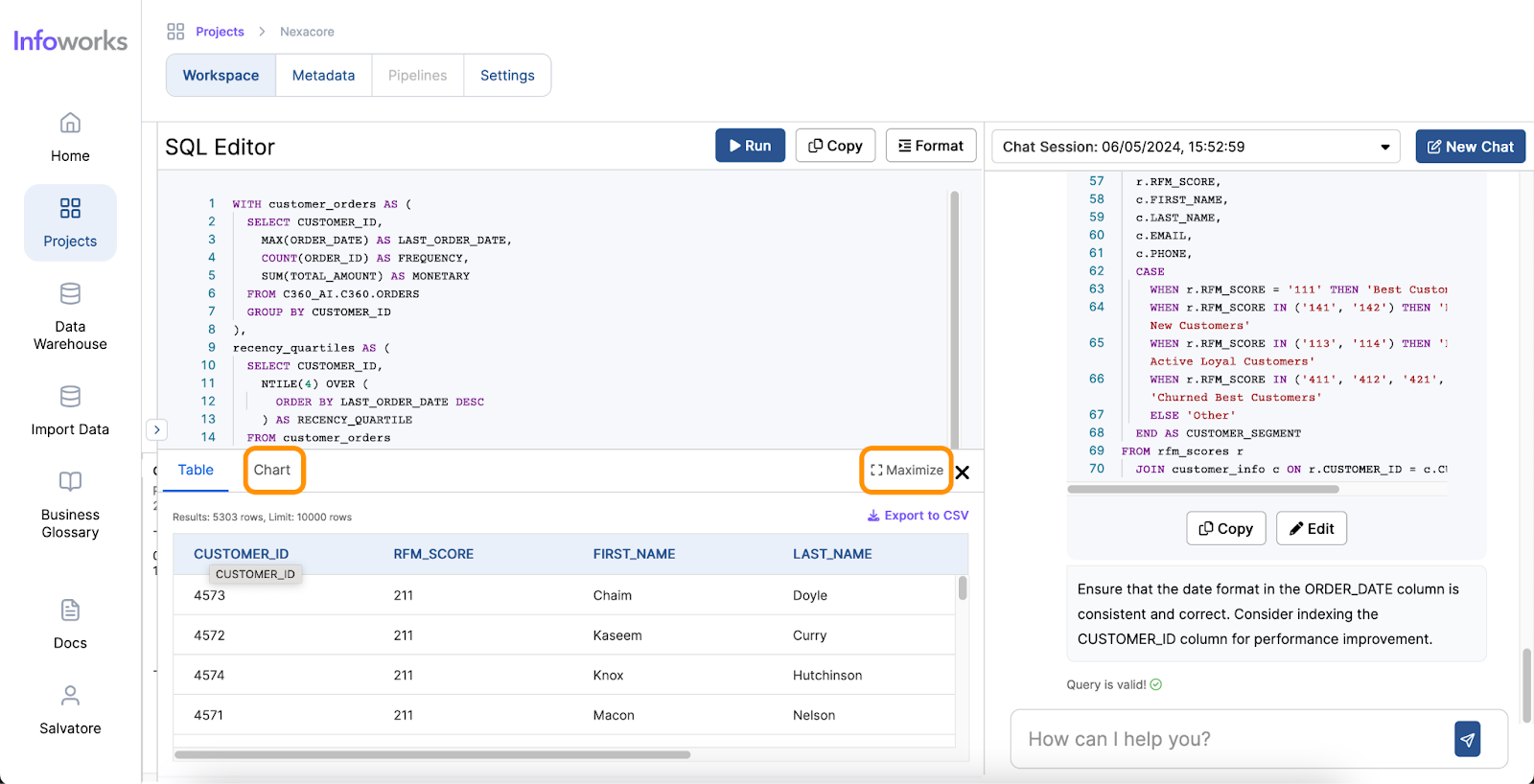
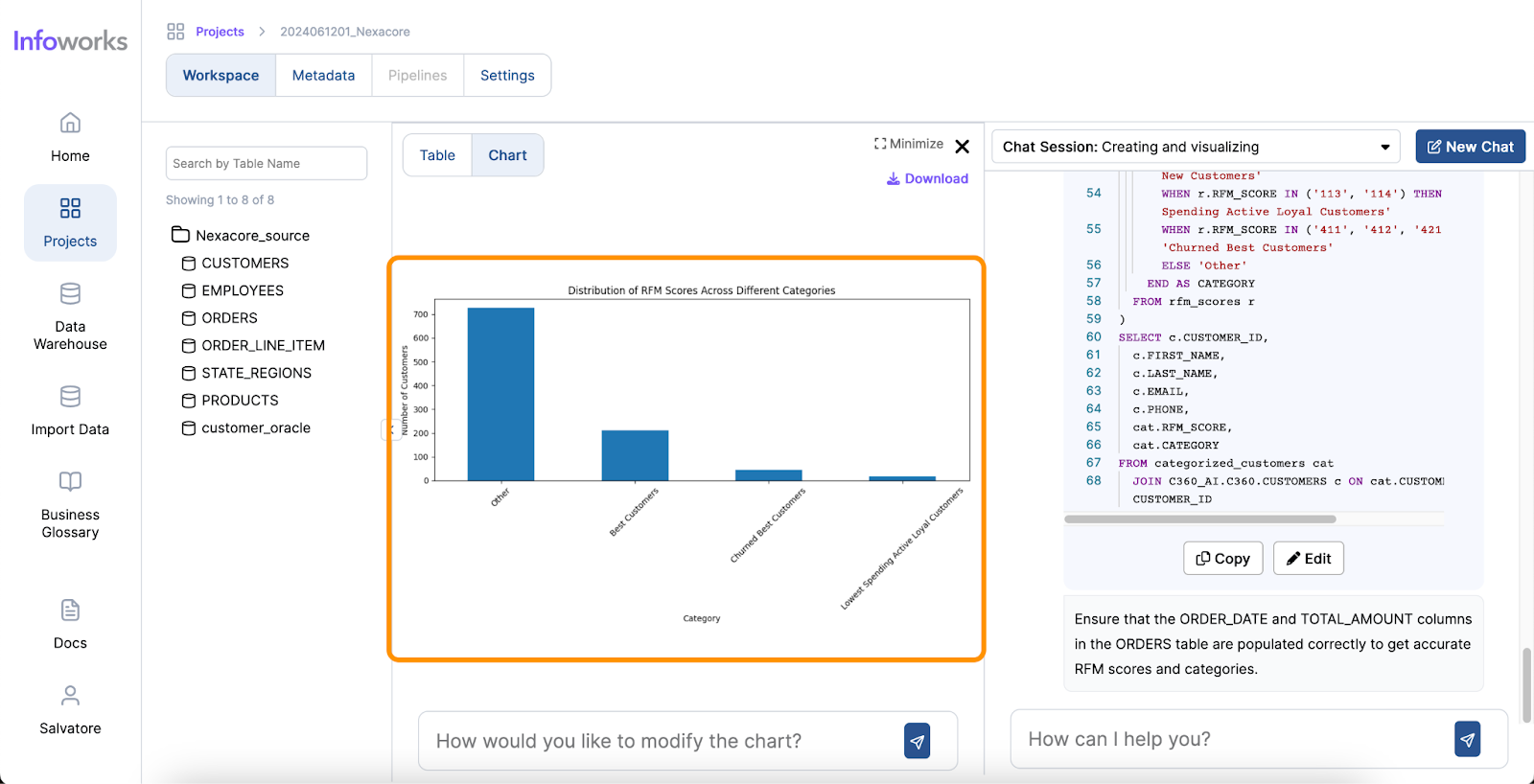
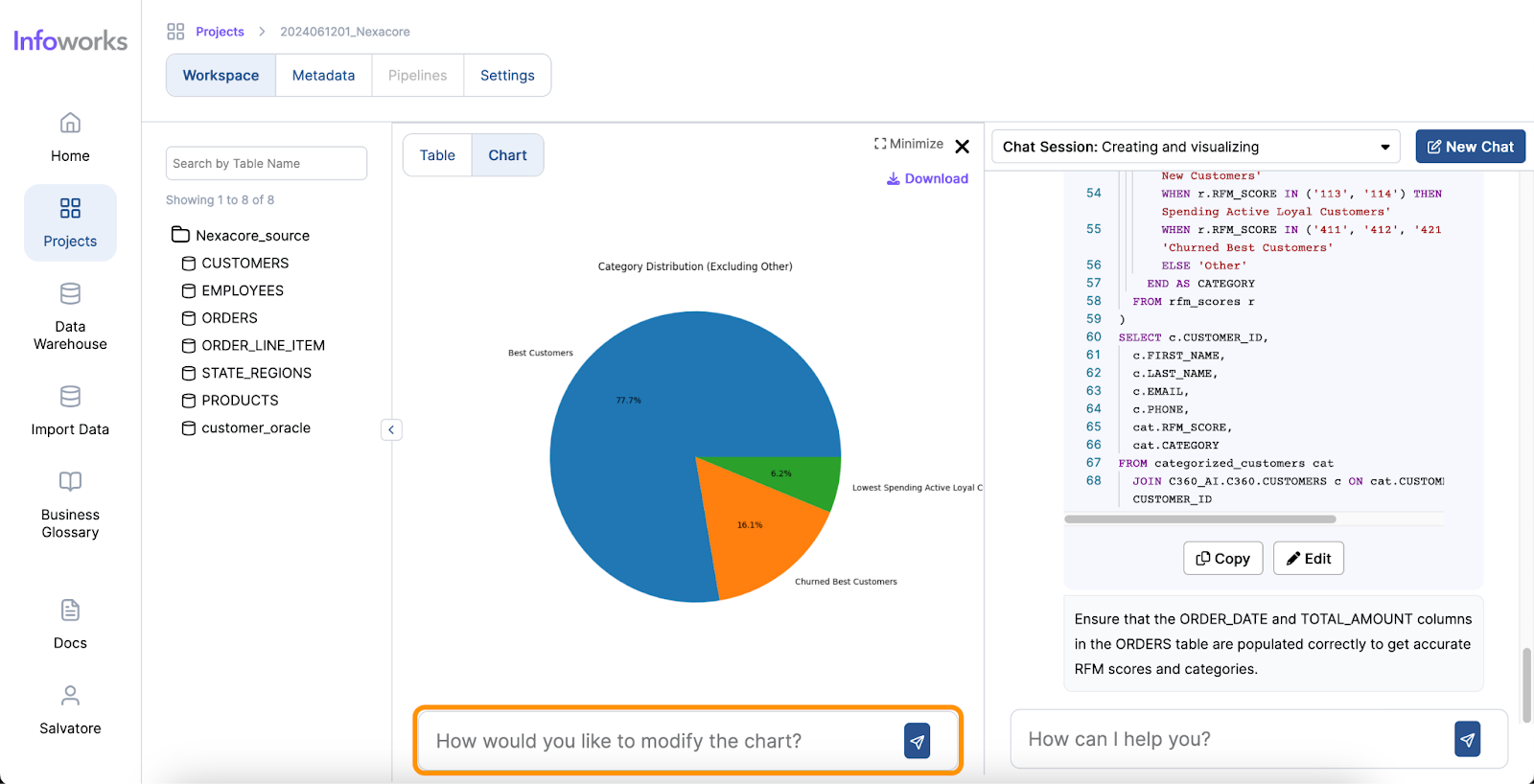
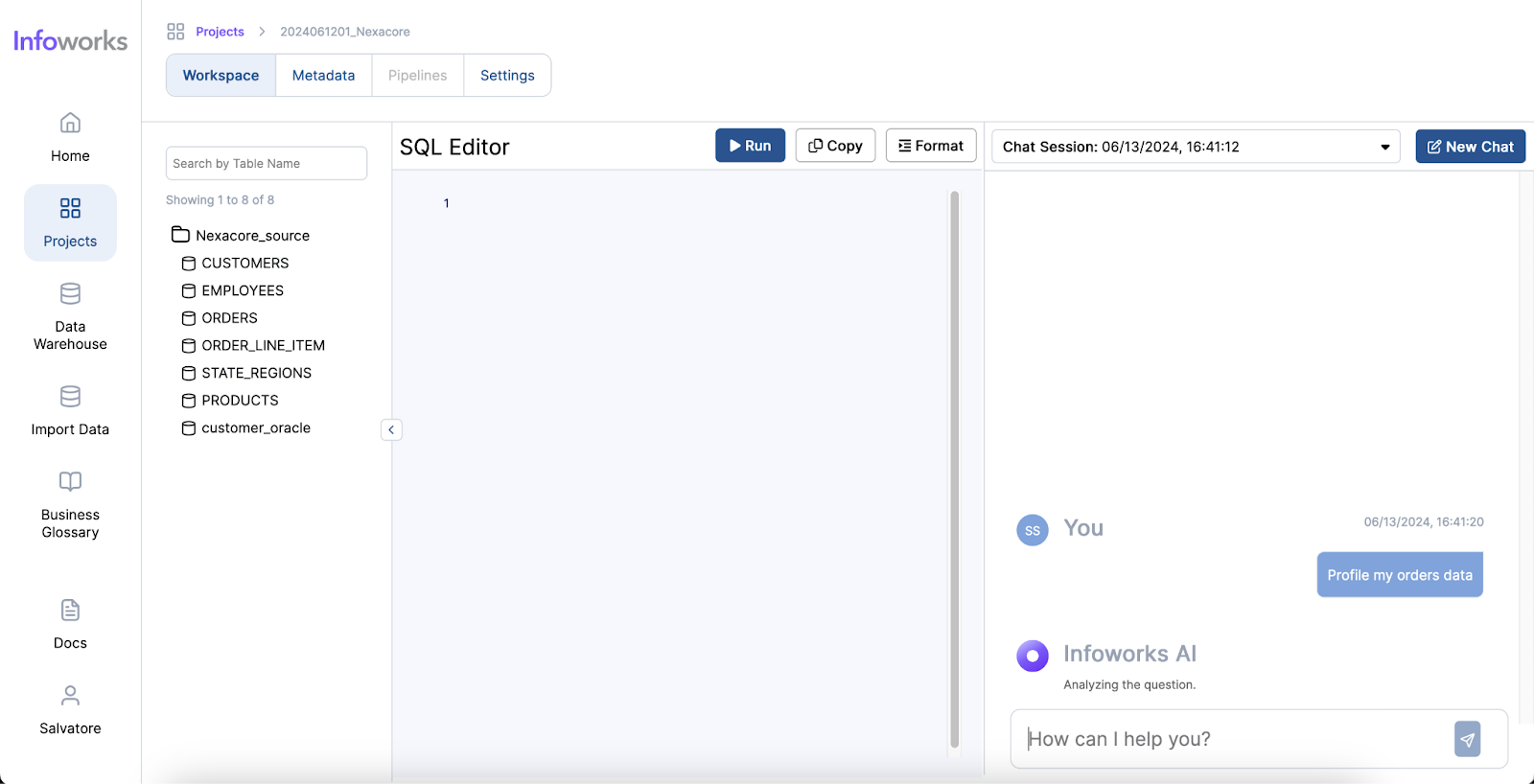
Infoworks excels in its wide range of supported operations and functionalities, making it a versatile tool for data analysts. The platform also offers automation for data discovery, data profiling and data cleansing, significantly simplifying these processes. Moreover, Infoworks AI enables the generation of SQL queries from natural language inputs and effortlessly creates charts and visual reports. These capabilities not only save time but also enhance the overall data analysis experience, making Infoworks AI a powerful and efficient tool for modern data professionals.
Cost-Effectiveness of Using Infoworks AI
Infoworks AI is designed to be a cost-effective solution for data analysis, providing significant savings compared to traditional methods. By integrating features such as data migration, cleansing, transformation, query generation, and visualization into a single platform, Infoworks AI optimizes resource utilization and reduces overall costs. Moreover, the increased accuracy and efficiency provided by Infoworks AI translate into better business outcomes, as data analysts can generate insights faster and with higher precision. This improvement in productivity and decision-making capabilities ultimately leads to cost savings and a higher return on investment, making Infoworks AI a smart, cost-effective choice for organizations looking to enhance their data analysis processes.
Conclusion
AI-powered text-to-SQL tools are game-changers for Data Analysts, making their work more efficient, accurate, and cost-effective. By leveraging these advanced tools, Data Analysts can focus more on deriving insights and less on the technicalities of data preparation and query writing, ultimately driving better business decisions. Adopt AI now, or risk falling behind other professionals.