

What is Infoworks Replicator?
The end-to-end automated solution for seamless Hadoop data and metadata migration
Enable the rapid migration of large-scale Hadoop data lakes to the cloud. All in a fraction of the time and with fewer resources required for legacy approaches.
Running as a service on your cloud, Infoworks Replicator maintains continuous operation and synchronization between on-premises Hadoop source and cloud destination clusters, ensuring data migration at scale without risk of data loss or business disruption.
The Infoworks Replicator difference
Changing the way enterprises migrate data to the cloud
Infoworks Replicator uniquely automates migration of large-scale Hadoop environments to the cloud, ensuring data continuity with no business disruption.

Automation
Powers faster migrations and reduces resource requirements to speed time to value.

Synchronization
Continuous operation and synchronization ensure zero business disruption.

Scalability
Migrate petabytes of data and metadata to any cloud seamlessly.

Extensibility
Automate your cloud data platform post-migration to accelerate deployment of new analytics use cases.
Learn more about Infoworks Replicator
The Infoworks Replicator at a glance
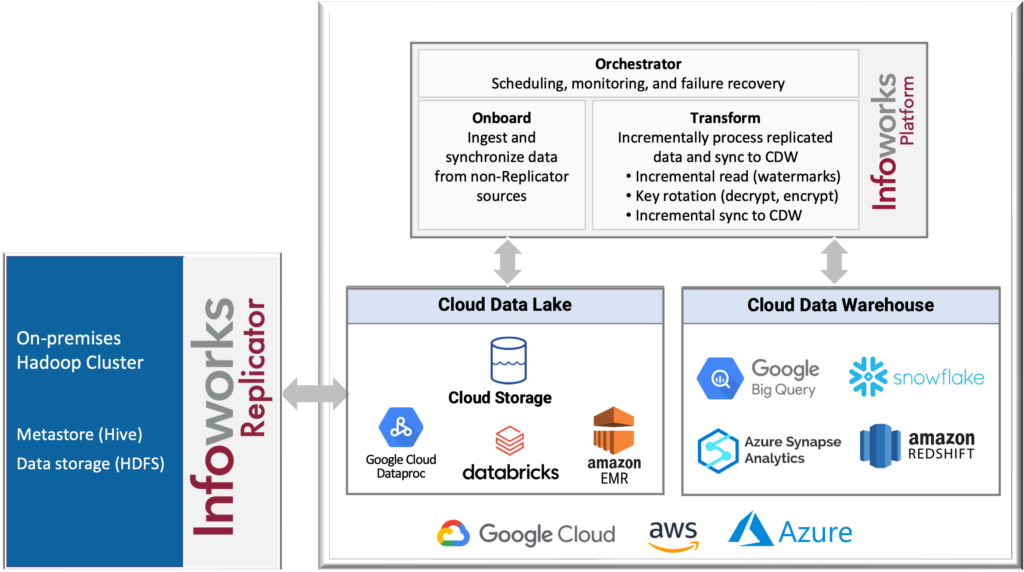
Why Infoworks Replicator is better
Migrate business-critical data to the cloud
Seamlessly replicate, synchronize, and modernize your data and metadata from Hadoop with Infoworks Replicator. Watch this video to learn more.
Automated code-free migration
End-to-end automation of Hadoop data and metadata to any cloud.
Automated fault tolerance
Automated restart upon network or node failure from point of failure removes significant overhead.
Integration with data transformation pipeline
Insert key rotation and any data shaping requirements into the end-to-end pipeline.
Scalability for petabyte size clusters
Control parallelism for computation and data replication tasks.
Continuous synchronization
Maintains continuous operation and data synchronization between Hadoop and cloud clusters.
Controlled network utilization
Allocate the network utilization allowed per replication session using static and dynamic network throttling.
Common data and file format support
Support for ORC, Parquet, Avro, Sequence, Partitioned, CSV, managed and external tables, bucketed tables, and text.
Flexible deployment modes
Deploy as source cluster, destination cluster, or a third cluster.
Extend your migration with the full Infoworks Platform to modernize your cloud data operations for agility and scale.
Latest Resources
Explore what Infoworks solutions can do for you.

 Press Releases
Press Releases Automated data engineering and Generative AI combine to addresses critical bottlenecks facing data professionals PALO ALTO, Calif., June 18, 2024 – Infoworks.io, the leading innovator in data engineering automation, announces the launch of Infoworks AI. This groundbreaking solution addresses the critical bottlenecks facing data professionals by leveraging advanced AI technology and Infoworks’ data engineering automation […]
Press Releases Automated Hadoop migration and cataloging solution delivers faster time-to-value for Databricks customers PALO ALTO, Calif., June 6, 2024 – Infoworks.io, the leader in data engineering software automation, today announced that it has added Databricks Unity Catalog integration to Infoworks Replicator – its industry-leading solution to automate migration of Hadoop data and metadata to the cloud. […]
Press Releases PALO ALTO, Calif., April 7, 2022 – Infoworks.io announces Infoworks Replicator 4.0, enabling migration of on-premises Hadoop data lakes to the cloud three times faster with one-third the resources required of traditional approaches. Digital transformation is a critical imperative for enterprises, migrating data and analytics to the cloud is an essential step. Infoworks Replicator has fundamentally changed the game.