

What is Infoworks Platform?
The only unified platform to accelerate cloud migration and modernize your cloud data operations – automatically.
The Infoworks Platform installs on your cloud and automates the migration of data, metadata, and workloads from Enterprise Data Warehouses and Hadoop Data Lakes to the cloud faster, with fewer resources, and at a fraction of the cost of traditional approaches. Our platform simultaneously establishes scalable and agile modern cloud data operations to automate the creation and deployment of new analytics use cases.
and workloads
other solutions
analytics use cases
and data warehouse environments
The Infoworks Platform difference

Accelerated migration
No-code migration of both data and metadata.
- Create and maintain metadata catalog, lineage, history, and audit trails
- Orchestrate migration pipelines

Workload portability
No-code migration of EDW and Hadoop workloads.
- Convert workloads to compute-agnostic visual pipelines
- Write to multiple targets (Databricks, Snowflake, Teradata) with a single pipeline
- Run workloads anywhere including Snowflake or Databricks without code changes

Post-migration agility & scale
Rapid, automated development of new analytics use cases.
- Choose the optimal compute source by decoupling pipelines from the compute layer
- Automate ingestion and CDC of new data sources from over 200 data source types using our Data Source Connector Directory
Learn more about Infoworks Platform
The Infoworks Platform at a glance
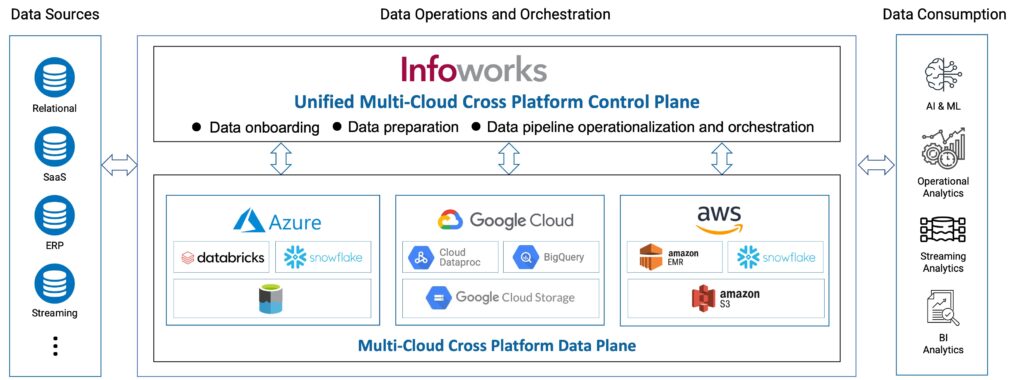
Learn more about Infoworks Platform
HOW IT WORKS
Unlock the value of your data
Infoworks Platform installs on your cloud and automates 90%+ of the tasks required for migration, operation, and orchestration.
Onboard
Data onboarding is the critical first step in operationalizing your data lake.
Our platform automates:
- Data and metadata ingestion
- Synchronization between on-premises and cloud
- Data governance and lineage
- Over 200 native data connectors
Prepare
Preparing data for analytics and optimizing for performance is the next step.
Our platform applies intelligent automation to:
- Data pipelines
- Data transformation
- Data models
- Workload migration
Operationalize
Run analytics at scale and realize the value of your data.
Our platform simplifies deployment and management of analytics use cases through automation:
- Promote to production
- Hybrid multi-cloud deployment
- Orchestration
- Workload migration
Latest Resources
Explore what Infoworks solutions can do for you.

 Press Releases
Press Releases Automated data engineering and Generative AI combine to addresses critical bottlenecks facing data professionals PALO ALTO, Calif., June 18, 2024 – Infoworks.io, the leading innovator in data engineering automation, announces the launch of Infoworks AI. This groundbreaking solution addresses the critical bottlenecks facing data professionals by leveraging advanced AI technology and Infoworks’ data engineering automation […]
Press Releases Automated Hadoop migration and cataloging solution delivers faster time-to-value for Databricks customers PALO ALTO, Calif., June 6, 2024 – Infoworks.io, the leader in data engineering software automation, today announced that it has added Databricks Unity Catalog integration to Infoworks Replicator – its industry-leading solution to automate migration of Hadoop data and metadata to the cloud. […]
Press Releases PALO ALTO, Calif., April 7, 2022 – Infoworks.io announces Infoworks Replicator 4.0, enabling migration of on-premises Hadoop data lakes to the cloud three times faster with one-third the resources required of traditional approaches. Digital transformation is a critical imperative for enterprises, migrating data and analytics to the cloud is an essential step. Infoworks Replicator has fundamentally changed the game.